Hi! After a long hiatus, I’m reviving the blog starting with conference notes.
“Mechanizing the Methodology” is a short but excellent talk given by Daniel Miessler at DEFCON 28 Red Team Village. I watched it way back in 2020 and forgot to share my notes at that time. But it is still very relevant, so it’s worth (re)discovering.
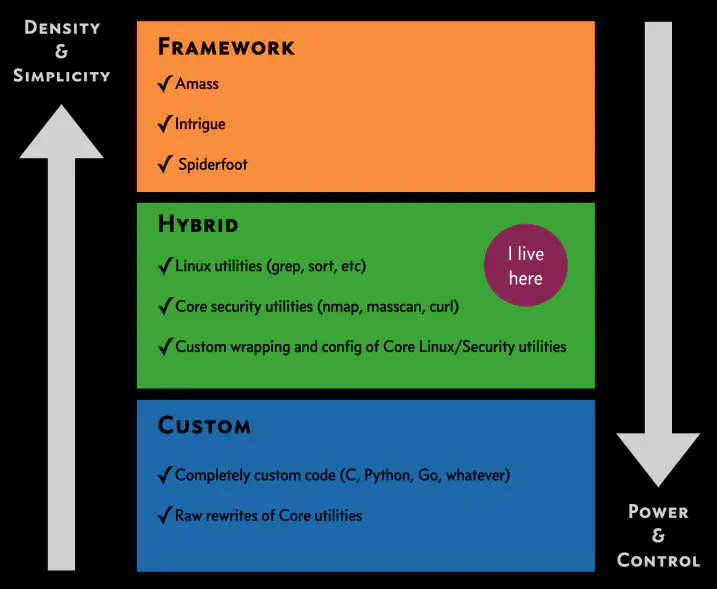
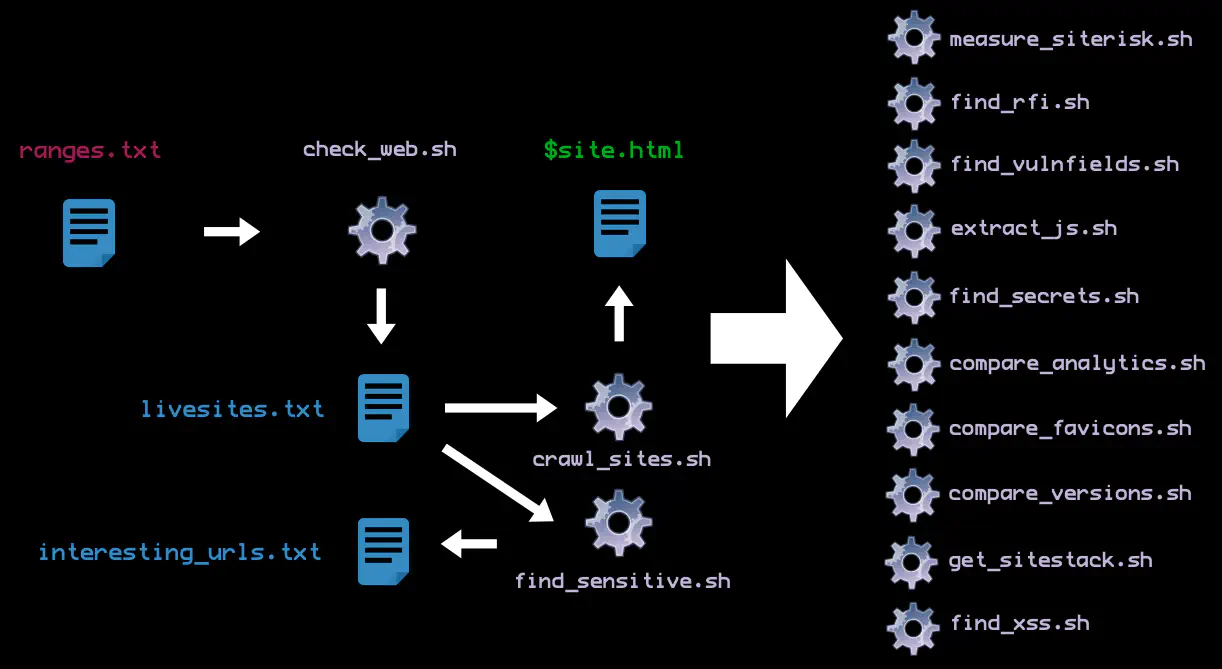
Some frameworks are amazing, save you tons of work and combine multiple steps. But they abstract steps away from you so you can’t easily see how they’re being accomplished
Daniel’s approach is hybrid: Building extremely small Unixy modules that leverage a low-level utility
Daniel uses masscan for speed and nmap for follow-up and NSE
Snippet from check_live.sh:
# Return any host that is listening on any of nmap's top 100 ports
# This is the nmap equivalent of `--top-ports 100`
$ masscan --rate 100000 -p7,9,13,21-23,25-26,37,53,79-81,88,106,110-111,113,119,135,139,143-144,179,199,389,427,443-445,465,513-515,543-544,548,554,587,631,646,873,990,993,995,1025-1029,1110,1433,1720,1723,1755,1900,2000-2001,2049,2121,2717,3000,3128,3306,3389,3986,4899,5000,5009,5051,5060,5101,5190,5357,5432,5631,5666,5800,5900,6000-6001,6646,7070,8000,8008-8009,8080-8081,8443,8888,9100,9999-10000,32768,49152-49157 -iL ips.txt | awk '{ print $6 }' | sort -u > live_ips.txt
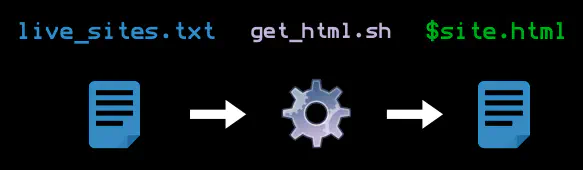
check_live.sh’s output is live_ips.txt which contains naked IP addresses ready to become input:
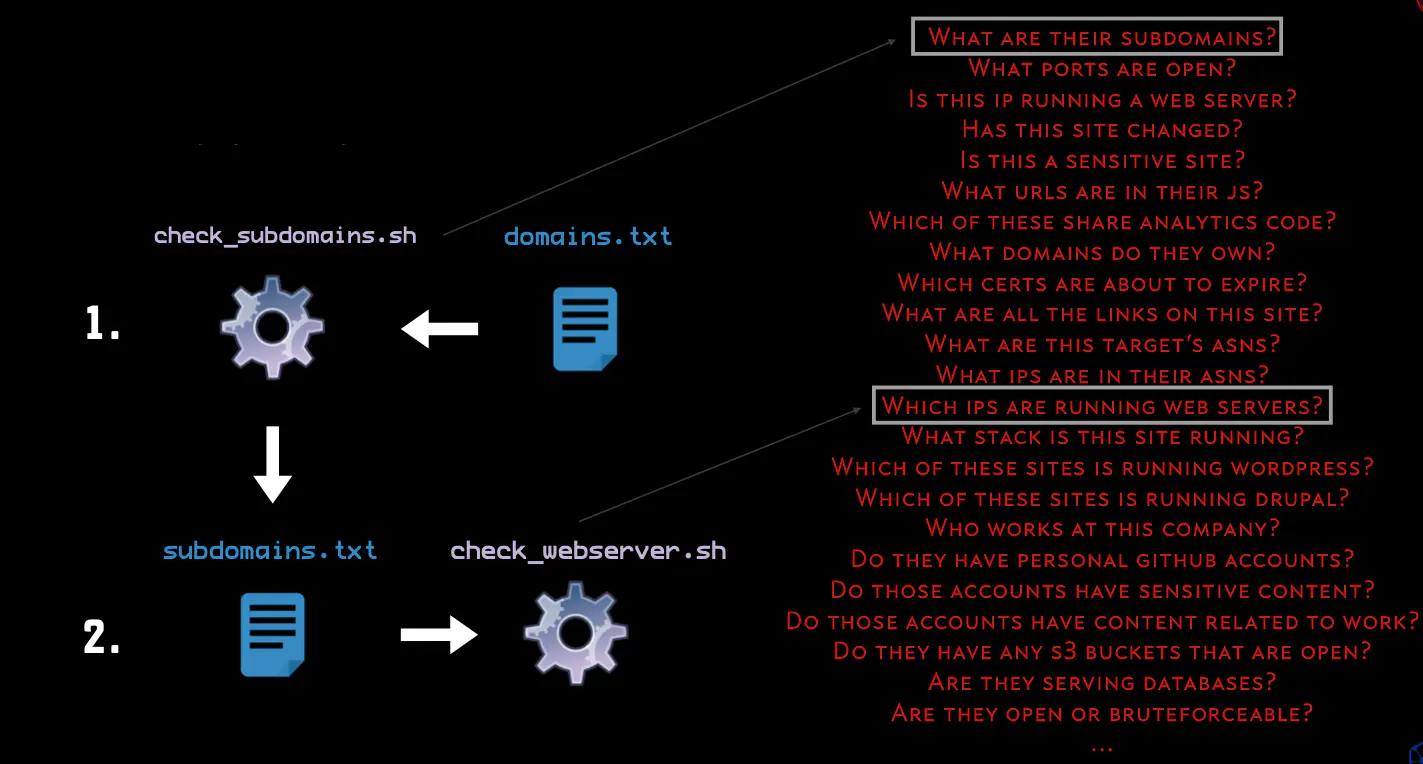
E.g. parse links, pull out JavaScript files, parse them to see if the page might be marked as sensitive, look for artifacts that indicate the tech stack, look for fields that are known to be vunerable to injections, etc
Daniel has a dozen of these modules just for parsing HTML
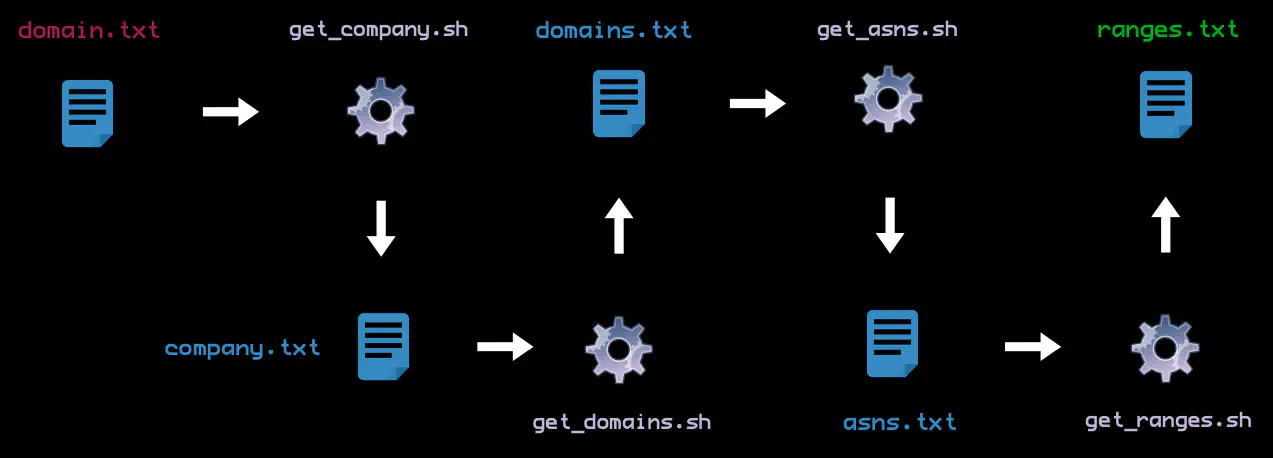
When you want to get the total, top-level scope for a given company, you need to pivot from known TLDs to other related TLDs (i.e. start with some known TLDs and look for others that are related)
One way to do that is to follow redirects to your target domain
Advantage: It helps find related domains that do not have the target’s name in the domain itself
Drawback: Results might include domains that redirect to your target without being related to it
Use email, Slack or other types of API-based notification to be alerted as soon as your automation finds something new
Daniel likes Amazon SES for sending emails and Slack for something richer. E.g.:
# Run sSMTP on Amazon SES to send emails
ssmtp "$RECIPIENT" < domain.notification
# Send a message to Slack using an Incoming Webhook
curl X POST -H 'Content-type: application/json' --data '{"text":"Hey, there’s a new yummy (open) PostgresDB @1.2.3.4"}' YOUR_WEBHOOK_URL
Note
Amazon Simple Email Service (SES) is a cloud email service provider that is relatively cheap and has a free tiers
sSMTP hasn’t been maintained since 2019 (remember the talk was given in 2020?). Debian Wiki recommends using an alternative like msmtp