On this page
Expand Collapse Hi, these are the notes I took while watching “The Bug Hunters Methodology v3(ish)” talk given by Jason Haddix on LevelUp 0x02 / 2018.
Links # About # This talk is about Jason Haddix’s bug hunting methodology. It is an upgrade of:
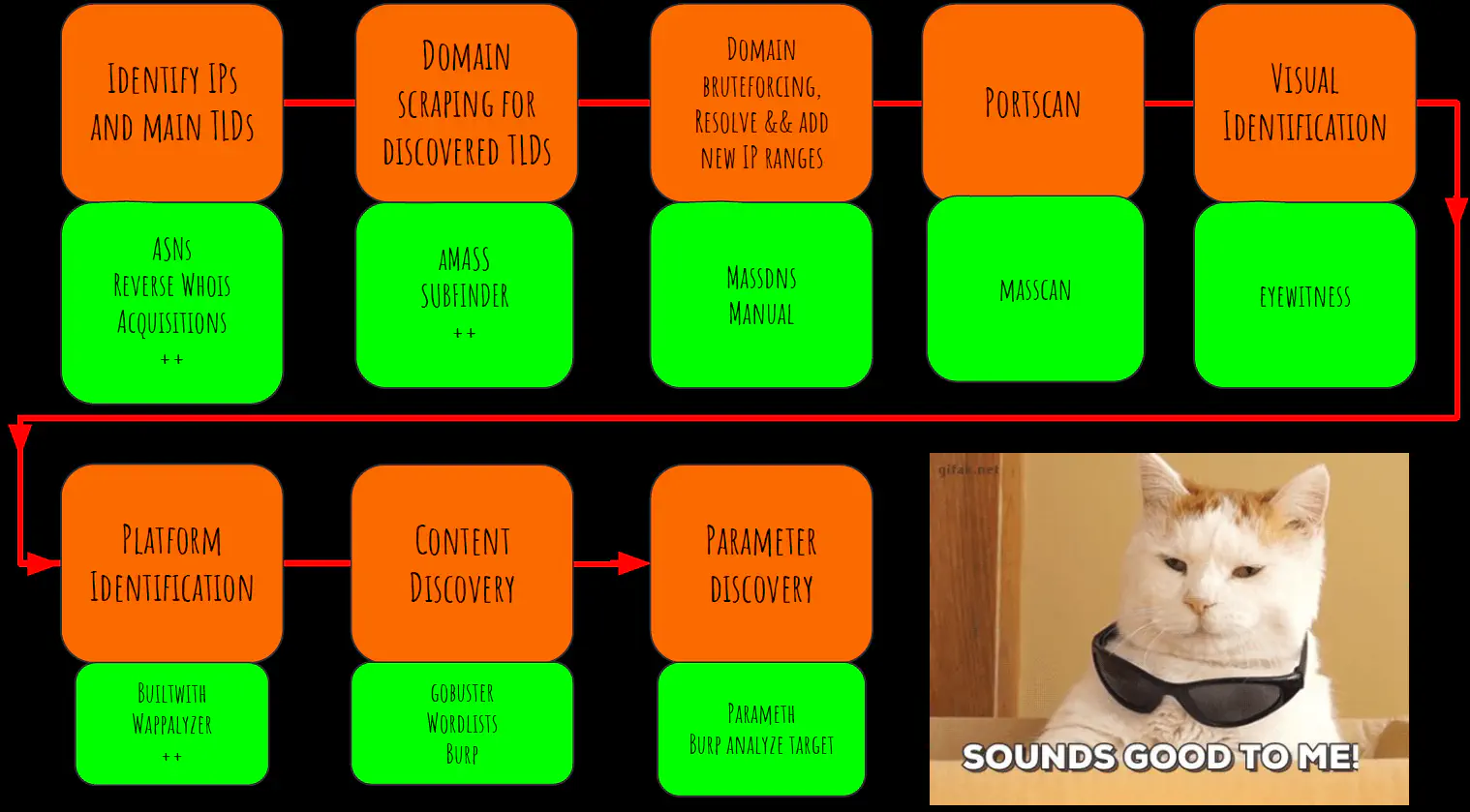
Light reading # Recon & Enumeration # Discovering IP Space # Goal : Given an org name, identify both their hosts/top-level domains & IP space
ASN’s # ASN = Autonomous System Number http://bgp.he.net Enter a company name or a keyword => ASNs listed, select 1 => IP ranges listed in Prefixes v4 tab One of the only sites that support search by keyword (e.g. tesla , tesla motors , tesla inc …) ARIN & RIPE # Rev WHOIS #
Shodan Organization # Discovering New Targets (Brands & TLDs) # Goal : Find new brands & Top-Level Domains
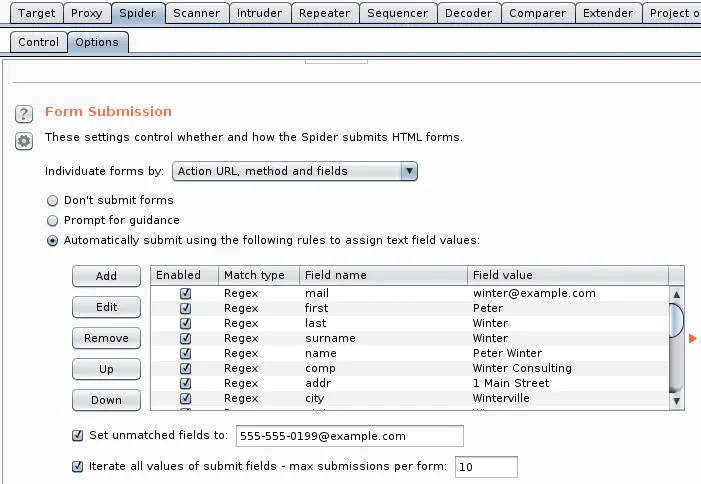
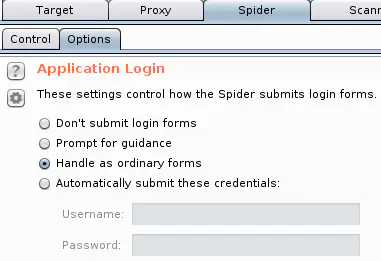
Brand/TLD Discovery # Acquisitions # Wikipedia the org Crunchbase acquisitions section Linked discovery # Burp spideringDemo (min 14.45)Turn off passive scanning (it generates a lot of results, taking up a lot of memory because we’re gonna spider a lot of sites)Scanner > Live Passive Scanning > Check Don’t scan Set forms to auto submit (if feeling frisky)Spider tab > Application login section > Check Handle as ordinary form
Spider tab > Form submission section > Automatically submit using the following rules…
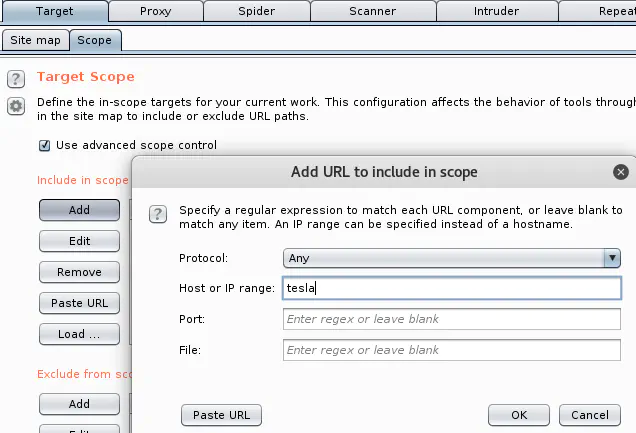
If you submit regular form & there’s an email generating form, you would blast tesla So use your discretion to configure these 2 forms. If it’s a small site with no email generating form, it’s OK to enable automatic forms submission Set scope to advanced control & use string of target name (not a normal FQDN)Goal: Show only links that have tesla in the URL in the Site map
Click yes for to "…stop sending out of scope items to the history…" Show only in scope items in the Target / Site map Manually walk + browse, then spider all hosts recursively Spidering can take 5 to 25 min depending profit (more targets)! Weighted link and reverse tracker analysis # Domlink
by Vincent Yiu Idea: Recursively looks at reverse whois programmatically based on who registered a domain, and then creates a link between those domains Usage: python ./domLink.py -d vip.com -o vip.out.txtDo a whois lookup on vip.com. Then from the WHOIS information, based on the registrar & other data, recursively look at any other WHOIS record that has the same information Hasn’t worked well for Jason yet but he likes the idea Builtwith
Idea: Links together the relationship of a site based on its analytics trackers (ie domains using the same analytics code) Usage: Relationships tab, Related Domains sectionGives you a heat map of how each domain is related to your target Helped him find sites that are related and in scope but not explicitly listed Others # Google dork for:the Trademark of the company: "Tesla © 2016" "Tesla © 2015" "Tesla © 2017" inurl:tesla or whatever trademark is at the bottom of the page the privacy policy link of the company Discovering new targets (Subdomains) # Goal : Finding subdomainsTwo main ways:Subdomain scraping : Find subdomains referenced online somewhere Subdomain brute forcing : Try to resolve subdomains based on a wordlist Subdomain scraping # It’s all about sources Probably 25 to 40 good sources . Examples:Ask.com crt.sh Hacker target https://dnsdumpster.com Ptrarchive.com DNSDB Search Bing Baidu Yahoo! Google Robtex! Censys CertDB Cert Spotter Netcraft Passive Total F-secure Riddler Dogpile Security Trails ThreatMiner VirusTotal Wayback Machine ThreatCrowd Tools you use must have the right sources and be executed relatively quickly Jason used to use Sublist3r & Altdns but now prefers using only Amass & Subfinder Amass # https://github.com/caffix/amass by @jeff_foleyUp to 22 sources Includes Reverse DNS methods & permutation scanning (dev-1.netflix.com, dev-2.netflix.com) Usage root@Test2:~/tools/amass# cat amass.sh
#!/bin/bash
mkdir $1
touch $1/$1.txt
amass -active -d $1 |tee /root/tools/amass/$1/$1.txt
root@Test2:~/tools/amass# ./amass.sh netflix.com
Subfinder # https://github.com/ice3man543/subfinder by IcemanMost sources included in Amass But also include Json output & a multi resolver for bruteforce… Idea: Integrate scraping & bruteforcing in a single subdomain tool Usage root@Test2:~/tools/subfinder# cat subfinder.sh
#!/bin/bash
mkdir $1
touch $1/$1.txt
subfinder -d $1 |tee /root/tools/subfinder/$1/$1.txt
root@Test2:~/tools/subfinder# ./subfinder.sh twitch.tv
Amass & Subfinder are enough # Their output is comparable. So script them together on the CLI, then sort and unique the output Used together, they cover about 30 sources Amass can run a little bit longer than subfinder if you include the permutation scanning but not too long to impact your workflow Other tools Jason used to use but not anymore :Enumall / Recon-NG (not great on sources or speed) Aquatone (not great on sources) but aquatone-scan is useful Sublist3r (same as above) Anything else for scraping ClouDflare Enum (although sometimes he “thinks about it”)He doesn’t use it but finds it interesting because he doesn’t understand the black magic behind how it works Not sure if it uses sources better than Amass & Subfinder but he doesn’t think so Subdomain Brute Forcing # Old tools:Fierce Blacksheepwall Dns-parellel-prober Knock.py They’ve been supplanted by Massdns Can run a million line dictionary in 30 sec Because it’s written in C and breaks up your wordlist into small pieaces & assigns each piece to a different DNS resolver in Parallel Subfinder alsoMight be as good as Massdns but Jason hasn’t tried it yet for bruteforcing CommonSpeak By @naffy & @shubs Content discovery wordlists built with BigQuery Subdomain data is awesome, Jason plans on adding it to all.txt But the URL data (URL paths) for content discovery has been less useful. It’s very app specific So Jason uses CommonSpeak for subdomain data but not URL data He also uses scans.io Jason’s setup # Use Massdns time ./subbrute.py /root/work/bin/all.txt $TARGET.com | ./bin/massdns -r resolvers.txt -t A -a -o -w massdns_output.txt -Try Subfinder Use Gobuster as the best non multi-resolver tooltime gobuster -m dns -u $TARGET.com -t 100 -w all.txt Environment setup:DigitalOcean $10/mo offer (1 GB RAM, 1 CPU, 30 GB SSD, 2TB transfer)Ubuntu 16.04 LTS Subdomains wordlist to use: all.txt Also use CommonSpeak & scans.io for subdomain data Other methods of finding subdomains # Enumerating targets # Port Scanning # Use Masscan By Robert Graham Fastest port scanner. Nmap takes forever if you do a full port scan on all hosts of an ASN Usage: masscan -p1-65535 -iL $TARGET_LIST --max-rate 10000 -oG $TARGET_OUTPUT Shell script to run dig on a domain, strip out the HTTP/HTTPS prefix then run MasscanBecause Masscan takes only IPs as input, not DNS names Use it to run Masscan against either a name domain or an IP range #!/bin/bash
strip=$(echo $1|sed 's/https\?:\/\///')
echo ""
echo "##################################################"
host $strip
echo "##################################################"
echo ""
masscan -p1-65535 $(dig +short $strip|grep -oE "\b([0-9]{1,3}\.){3}[0-9]{1,3}\b"|head -1)
--max-rate 1000 |& tee $strip_scan
Credential bruteforce # Masscan -> Nmap service scan-og -> Brutespray credential bruteforce
Use Masscan with the -oG Re-scan the output with Nmap version scanning Pass the output to Brutespray Usage: python brutespray.py --file nmap.gnmap -U /usr/share/wordlist/user.txt -P /usr/share/wordlist/pass.txt --threads 5 --hosts 5 Visual identification # Not all subdomains previously scraped off the internet are still up, some are the same (DNS redirects) & we don’t know which protocol they are on (HTTP or HTTPS) We could port scan ports 80 & 443 But another way to find out what is up and unique is taking screenshots with Eyewitness Eyewitness # Eyewitness takes a list of domains without a protocol, visits each one with a headless browser, takes a screenshot & dumps them to a reportUsage: python Eyewitness.py --prepend-https -f ../domain/tesla.com.lst --all-protocols --headless => tells you which domains redirect to the same app, which domains are interesting & should be hacked first Why not Aquatone or Httpscreenshot: Because Eyewitness tries both HTTP & HTTPS protocols Eyewitness isn’t foolproof: The headless browser doesn’t always resolve, timeout issues, it can take a while… => Use Eyewitness for large targets. => But if you have a small list (~20 hosts), use sed or awk to add HTTP & HTTPS to every subdomain, then load them up manually with the CLI in the browser Or use OpenList , a Chrome extension: Give it your list of URLs & it’ll open them in multiple tabs What to look for? # Not interesting:
Anything that redirects to the main site Help portal , email portal or OWA portal . They’re usually hardened out of the box (not always but most of them time)Interesting:
Custom apps that are not the main websiteThey’ve probably spent less time with security on those sites than the main domain Non standard Web ports:
There’s a list of ~20 very common non-standard Web ports (i.e. services not running on port 80 or 443) You can find them by port scanning with Masscan & service scanning with Nmap Then add them to Eyewitness with the --add-http-ports or --add-https-ports options. Wayback enumeration #
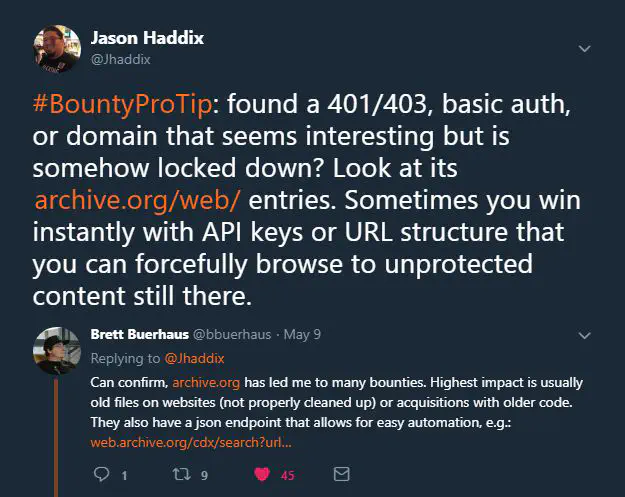
Also useful when you find subdomains that look juicy but don’t resolve Example: Site protected with Basic Auth but an old version cached by Wayback Machine has configuration information of a server on the front page. Tools Retire.js
Builtwith
Wappalyzer
burp-vulners-scanner
A lot of memory is needed to use many Burp extensions on large scope bounties !
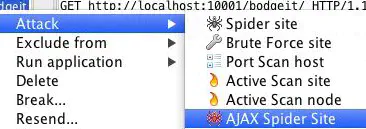
Parsing JavaScript # Generally automation doesn’t handle JavaScript very well You could parse JS files manually but it’s not possible on large scope bounties Many people assume Burp automatically parses JS files, relative paths, etc, and is able to execute all JS it finds. Burp is good but not perfect for this Tools for better coverage of heavy JS sites:ZAP Ajax Spider
Basically spiders the site with a headless browser
LinkFinder
Extracts absolute & relative URLs from JS files JSParser
Burp pro only Similar to LinkFinder but not as good Feeding these tool:Right click on any domain, choose Engagement tools then Find scripts . Clic on Search (finds all references to JS in all scripts) and Copy selected URLs Pass URLs found to one of the JS tools Visit the new URLs links these tools found in JS scripts Content discovery / Directory bruting # Idea: Bruteforcing URL paths His favorite content discovery tool & wordlistGobuster The tool he uses because it’s in Go, fast & is extensible time ./gobuster -w --seclists/Discovery/Web_Content/raft-large-words.txt -s 200,301,307 -t 100 -u https://www.tesla.comcontent_discovery_all.txt Includes both files & URL paths Includes Robots disallowed & Raft Robots disallowed & Raft are old but still really useful He prefers them to scan.io data or other lists because:Robots disallowed & raft parsed all the robots.txt files on the Internet & sorted by occurrence the paths that people didn’t want you to visit scans.io data parses whole websites & gives you occurrences of files & paths so it’s not stuff that they don’t want you to find, just occurrence or URLs => not useful for a pentester/bug hunter Other tools Other wordlists Parameter bruting? # Summary of the whole recon methodology #
Common vulnerabilities # XSS # Not a lot of changes 2 new super useful frameworks for instrumenting Blind XSS: Server Side Request Forgery (SSRF) # Nothing new about the method of testing When testing against a cloud environment, what do you look for?cloud_metadata.txt Insecure Direct Object Reference # IDOR - MFLAC # One of the most common bug classes he sees across Bugcrowd as far as occurrence & severity Pay attention to:all numeric IDs anything that looks like a hash anything that looks like an email that you could change to something else so that you can get access to somebody else’s account Common locations of IDOR bugs/vulns # | ———————- | ——————— | —————— |
| {regex + perm} id | {regex + perm} user | |
| {regex + perm} account | {regex + perm} number | |
| {regex + perm} order | {regex + perm} no | |
| {regex + perm} doc | {regex + perm} key | |
| {regex + perm} email | {regex + perm} group | |
| {regex + perm} profile | {regex + perm} edit | REST numeric paths |
Example: http://acme.com/script?user =21856
Infrastructure & Config # Subdomain takeover # Cloud providers
Heroku Github Tumblr Shopify Squarespace Salesforce Desk Amazon Webservices Unbounce Uservoice SurveyGizmo Fastly Zendesk Instapage Dyn Amazon Cloudfront HubSpot FastMail WPengine Check for CNAMES that resolve to these services. If the service has lapsed , register & profit!
can-i-take-over-xyz
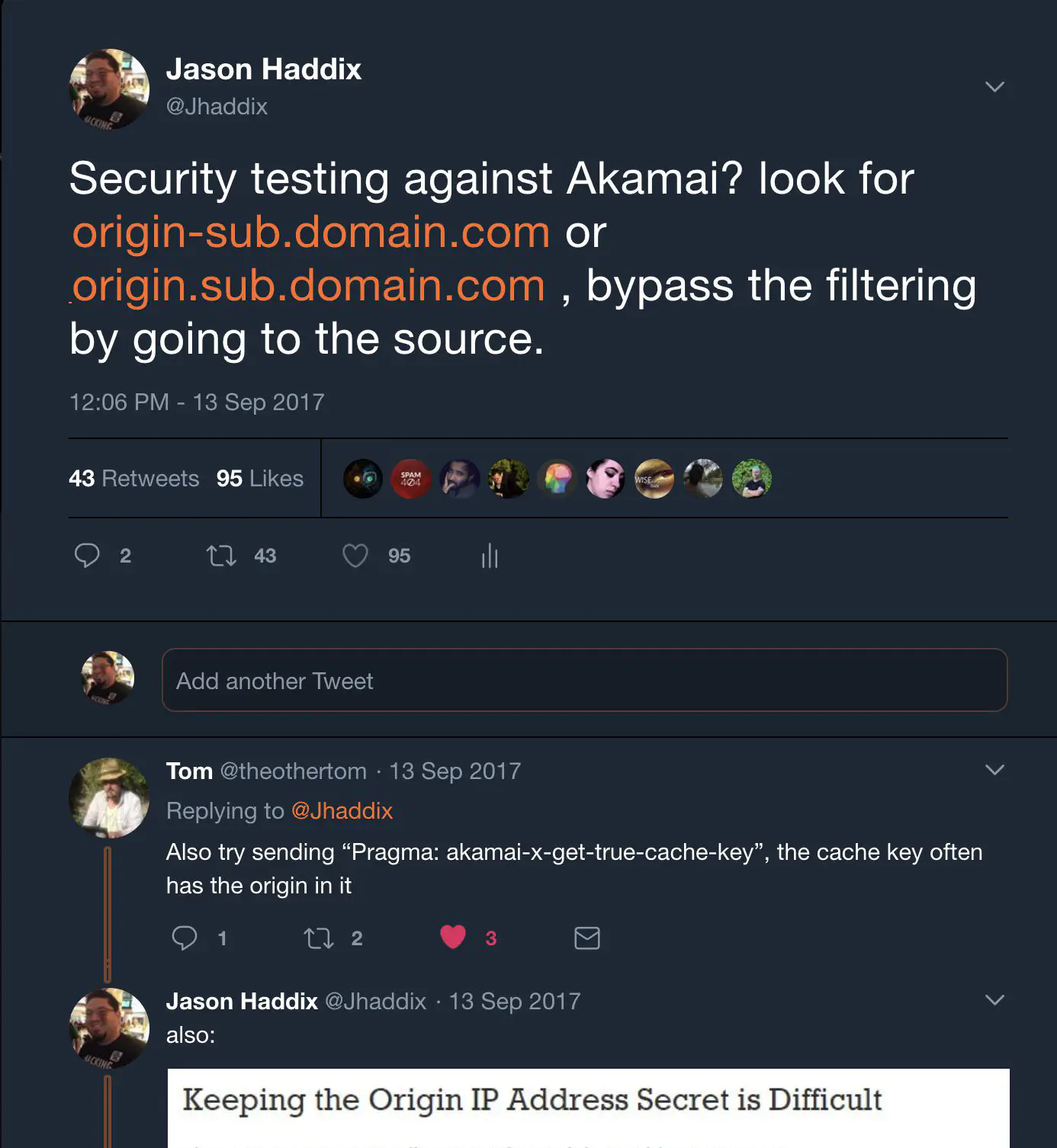
S3Scanner Tool to find open buckets related to your target company Give it a file with sources of either the full URL, the bucket region, just a domain name or a bucket name WAF # It’s common for bug hunters to get banned by WAF or CDN vendors security productsPredominant WAFs: Cloudflare & Akamai Dedicated WAFS SolutionsEncoding (Meh)Finding origin
[Finding dev If a WAF blocks you on domain.com, try bypassing it by going to:dev.domain.com stage.domain.com ww1/ww2/ww3…domain.com www.domain.uk/jp/ … (regionalized domains)… Even though they serve the same app, the WAF might not be configured to protect those domains
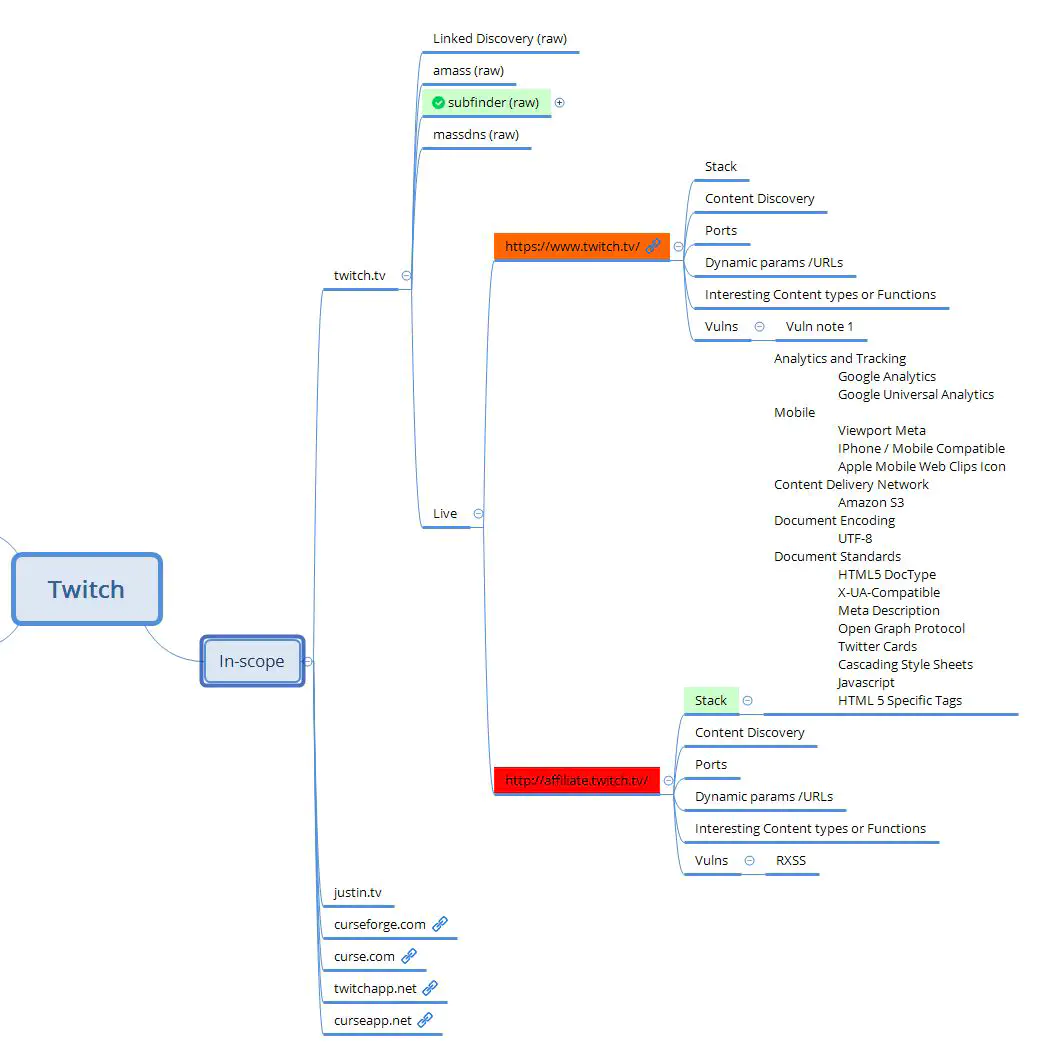
[ Xmind Organization # Using this semi automatic methodology, you’ll end up with a lot of artifacts from a lot of tools. => It’s hard to track a large scope bounty well Many people use Burp Highlighting or Burp’s inline tools to keep track of this stuff But Jason prefers Mind mapping with Xmind to track all his tool usage & progress Example:
Linked Discovery (raw), amass (raw)… : raw output of the tools Live: The actual site he’s testing Color highlightingGreen w/ checkmark = Done Orange = Progress Red = Vulnerable
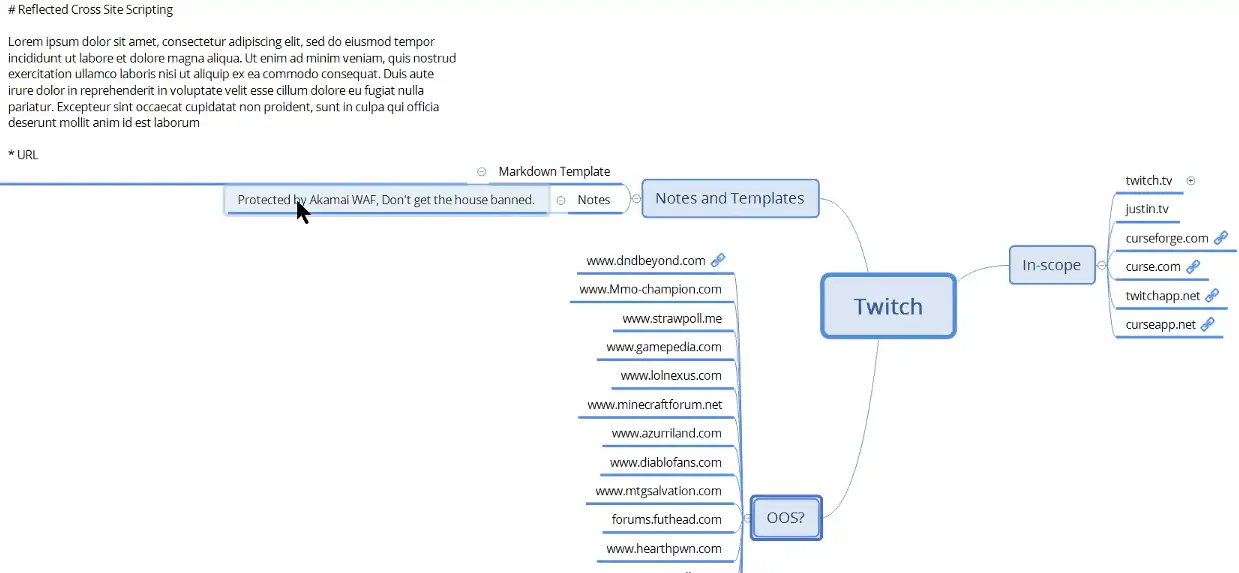
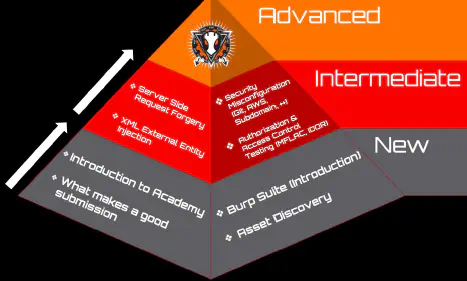
Markdown template: Templates for all his common findings on this bug bounty program (you’ll often find the same vuln accross multiple hosts on large scope bounties) The future of TBHM # Bugcrowd University is the future of TBHMIt’s a new training course including all information in TBHM slides + new topics An open source training curriculum for each bug class New content will be released every quarter You can contribute to the open source slides, present them in local meetups or null/Defcon meetups Initial topics will be:
Intermediate level: P1 bugs submitted by super hunters that get paid out really high See you next time!


 (https://twitter.com/Jhaddix/status/908044285437726726)]
(https://twitter.com/Jhaddix/status/908044285437726726)]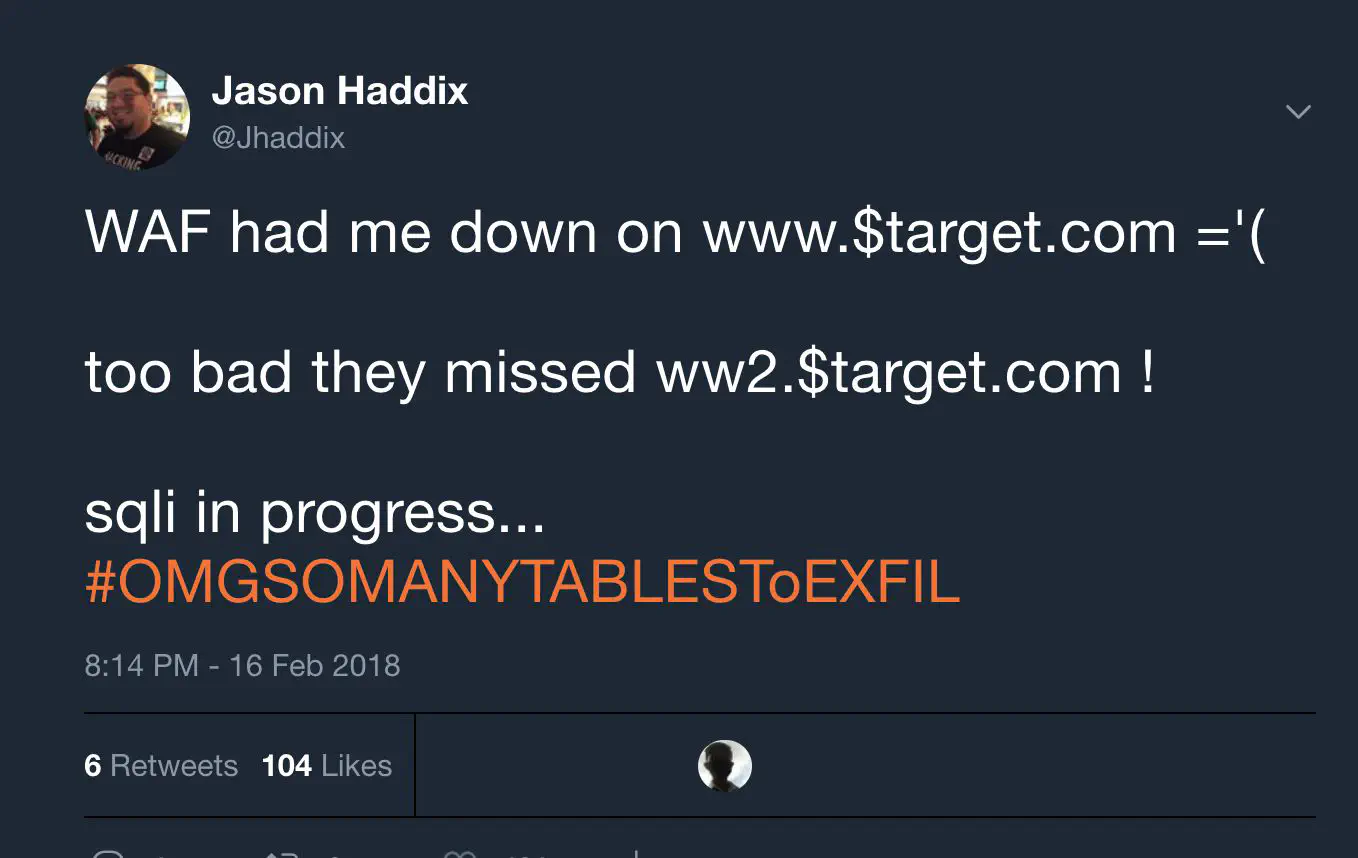 (https://twitter.com/Jhaddix/status/964714566910279680)]
(https://twitter.com/Jhaddix/status/964714566910279680)]